


Keep up with what matters to you.
Discover keeps you up to date on all your favorite topics. Follow everything from sports teams and movies to celebrities, hobbies, and more. Plus, you can dive deeper on any of your interests with a single tap.


Find what you need.
Get info, ideas and inspiration on the go. The Google app can help you plan your next evening out (or in), with the perfect dinner, the right movie, and much more.

Explore deep and wide.
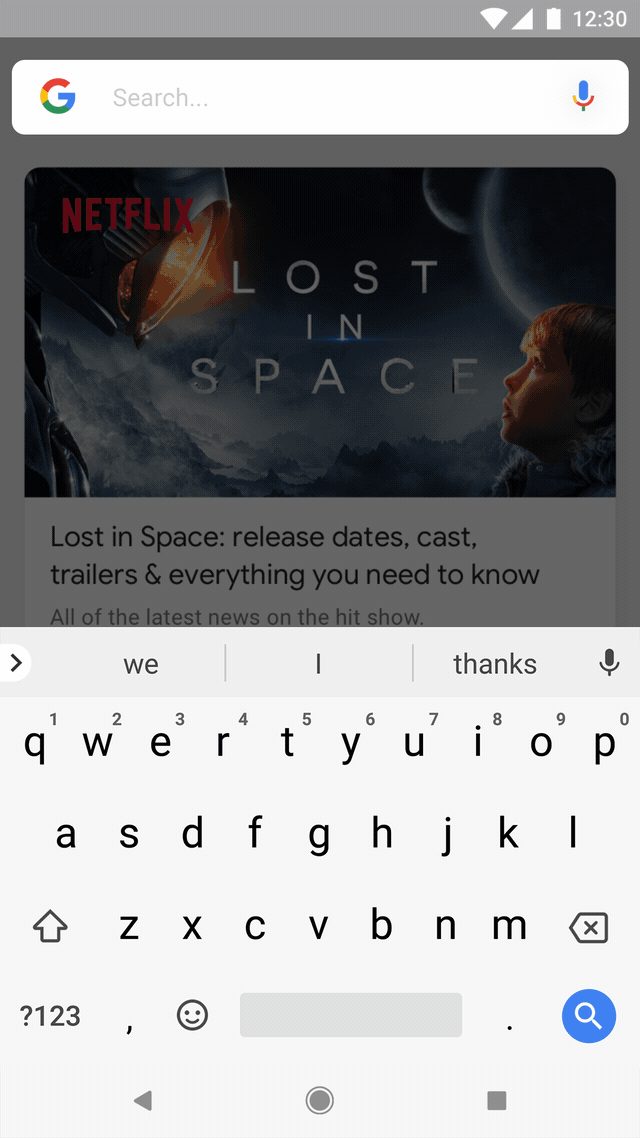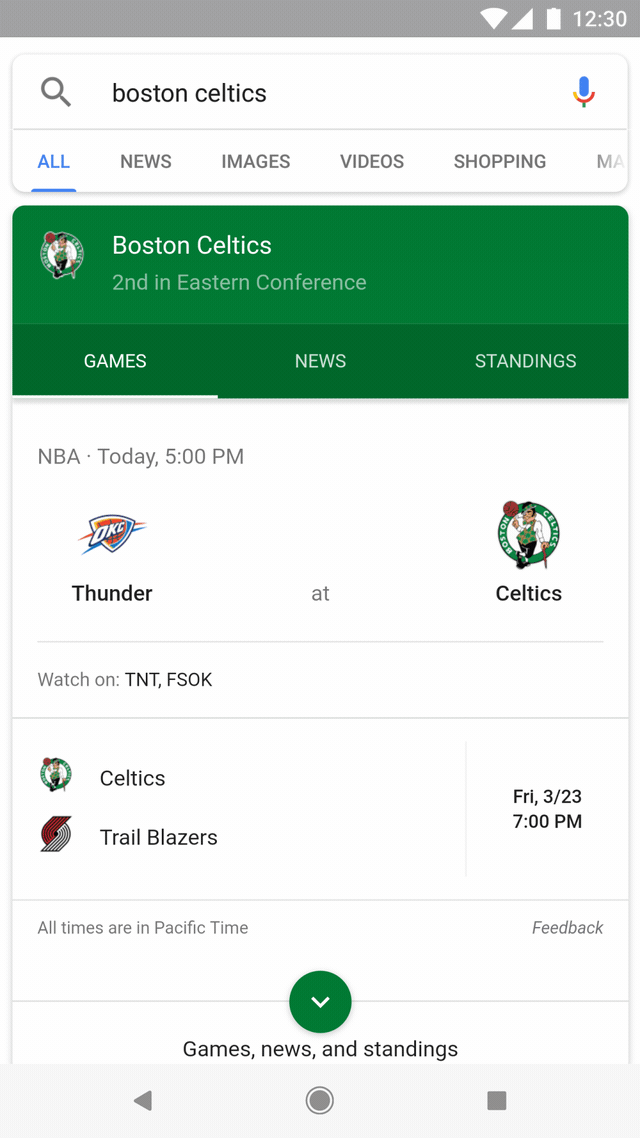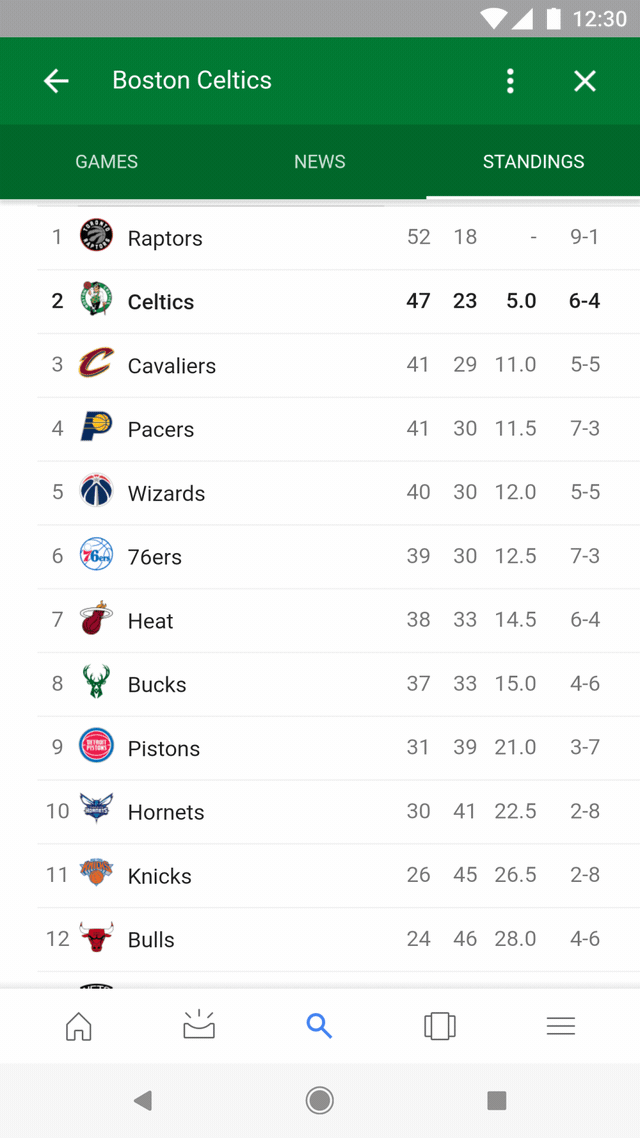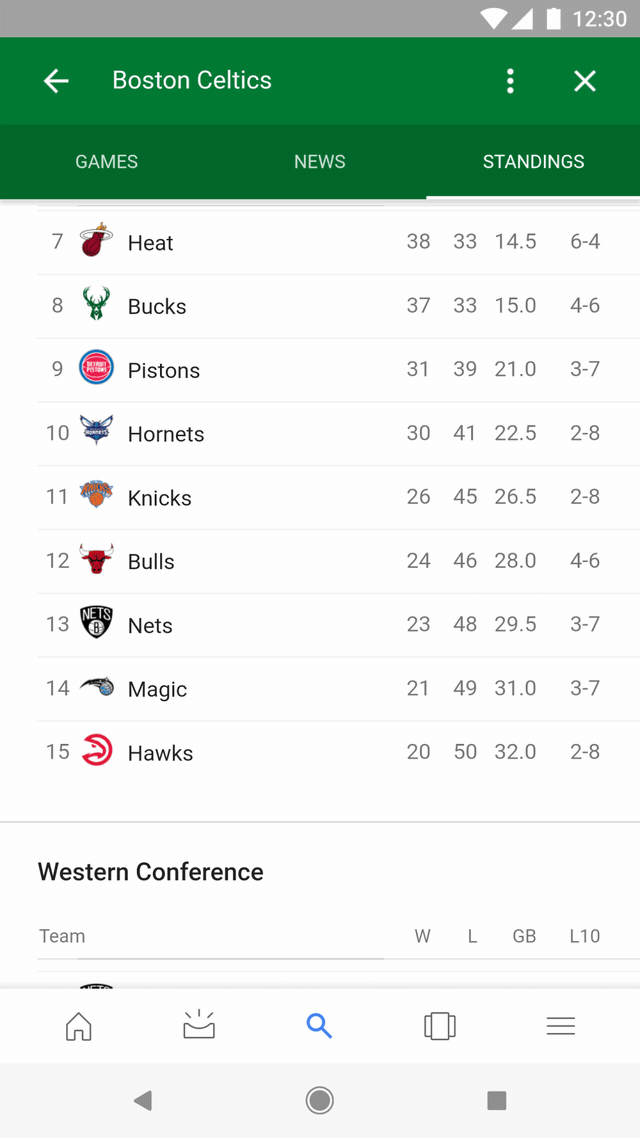
Immerse yourself in popular categories like dining, entertainment, sports, and more. Whether you’re looking for something specific, browsing, or just wondering what other questions you should ask, there’s a ton to explore.
